(来源:财信证券研究)
GTC 2026召开,产品创新拉动AI产业发展
分析师:何晨 从业人员登记编号:S0530513080001
分析师:袁鑫 从业人员登记编号:S0530525080001
分析师:周剑 从业人员登记编号:S0530525090001
研究助理:汪颜雯
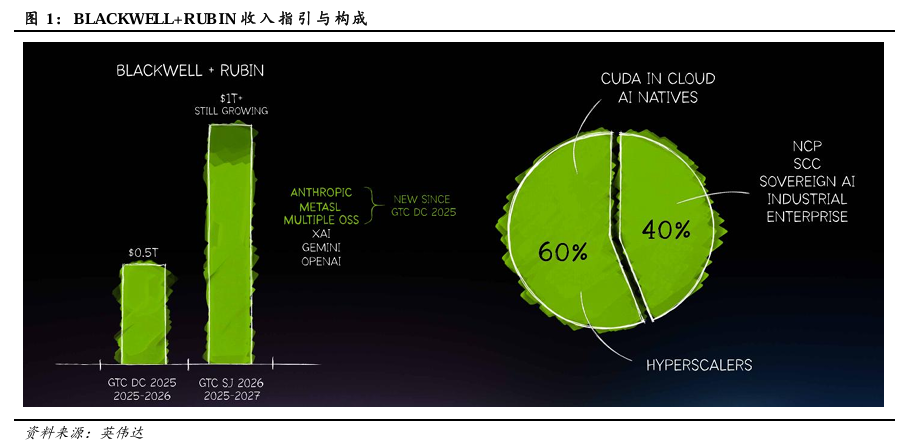
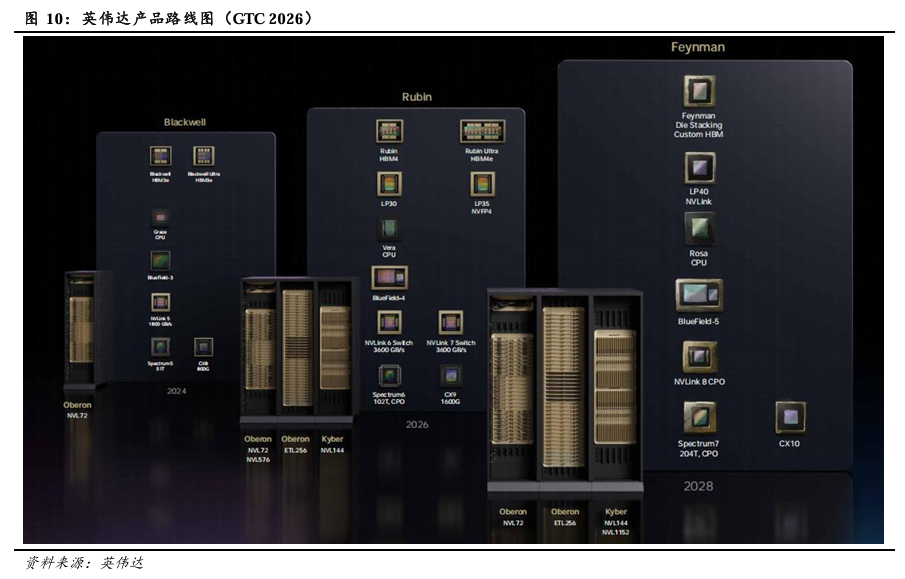
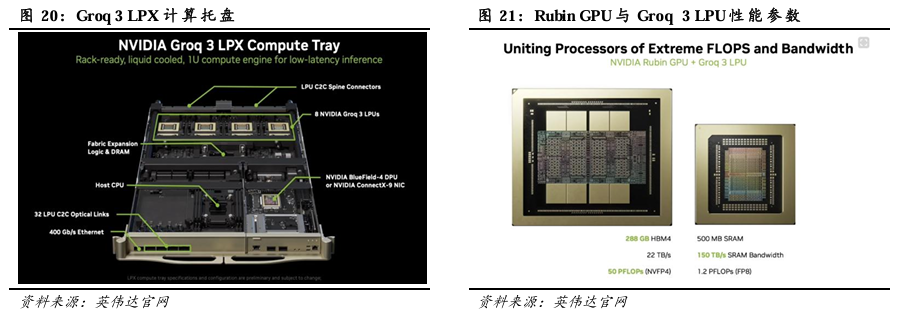
GTC 2026 黄仁勋演讲回顾:1)预计Blackwell与Rubin产品在2025-2027年实现收入约10000亿美元,此前在GTC 2025上预期Blackwell与Rubin产品在2025-2026年实现收入约5000亿美元,英伟达收入有望在2026-2027年实现高速增长。2)发布Vera Rubin POD,引入LPX机架。Vera Rubin POD由16*Vera Rubin NVL72机架+10*Spectrum-6 SPX 以太网机架+10*Groq 3 LPX机架+2*Vera CPU机架+2*BlueField-4 STX存储机架组成。其中Groq 3 LPX 机架,搭载256个LPU处理器,配备128GB片上SRAM和640 TB/S的纵向扩展带宽。LPU专为智能体系统的低延迟和长上下文需求而设计,LPX与Vera Rubin协同部署有望为AI供应商拓展营收机遇。LPX机架预计将在2026年下半年面世。3)推理市场分级,高性能服务器触及更多市场。将需求划分为Free、Medium、High、Premium、Ultra等场景,Rubin NVL72、Rubin NVL72+LPX等高性能服务器能够触及更多高付费意愿场景,从而可实现更高收入规模。每GW的Blackwell、Rubin、Vera Rubin NVL72+LPX AI工厂的年营收潜力分别为300、1500、3000亿美元。4)发布产品路线图。Rubin平台预计在2026年问世,机架形式有望从Blackwell平台的Oberon NVL72拓展至Oberon NVL72、NVL576,Oberon ETL256,Kyber NVL144。Feynman平台预计在2028年问世,机架形式预计为Oberon NVL72,Oberon ETL256,Kyber NVL144、NVL1152。
LPX机架与Kyber Mid-plane有望拉动PCB需求。我们维持2026年 AI PCB市场规模有望在量价齐升逻辑下同比增长110%,实现翻倍增长的判断。LPU及Kyber正交板有望进一步拉动AI PCB市场规模增长。1)LPX PCB单价有望进一步增长,并实现大规模出货。单价有望进一步增长,LPU计算托盘集成8颗LPU,单个机架搭载32个计算托盘,共256颗LPU,配备128GB片上SRAM和640 TB/s的纵向扩展带宽。LPU机架内需要处理大量数据吞吐且实现极低延迟的通信,有望对PCB层数、材料及工艺提出更高要求,推动PCB价值进一步上涨。LPU有望实现大规模出货,考虑Vera Rubin POD中Vera Rubin NVL72与LPX机架比例为16:10,可得POD中Rubin GPU与LPU比例约为1:2(16*72:10*256),Rubin POD有望拉动LPU大规模出货。2)Kyber Mid-plane技术路线确定性提高。GTC 2026大会上展出Kyber机架下的Compute Tray、Mid-plane、Switch Tray,使用PCB进行正交连接的确定性提高,PCB价值有望进一步增长。
Rubin平台架构创新,存储需求有望持续释放。1)Rubin平台创新AI存储架构,驱动存储增量跃升。推出基于BlueField-4数据处理器的推理上下文记忆存储平台,单机柜存储容量实现跃升。Rubin NVL72单机柜HBM内存达到20.7TB,总容量较Blackwell平台提升约1.5倍;单机柜内LPDDR5X总容量达54TB,较Blackwell平台提升约2.5倍。BlueField-4 DPU通过4颗DPU管理150TB内存池直连GPU,为每颗GPU额外拓展16TB上下文空间,这一架构变革直接推动单机柜NAND需求从830TB飙升至近2PB。2)LPX机架创新SRAM增量需求。Groq 3 LPU单颗芯片集成500MB片上SRAM,虽然与每个Rubin GPU上容量高达288GB的HBM4相比,仅为其1/500。但SRAM提供高达150TB/s的带宽,较HBM4 22TB/s带宽提升近7倍,可满足需要极致低延迟的Token生成任务。在英伟达的LPX机架级设置中,8颗LPU芯片组成一个计算托盘,基于Groq 3 LPU芯片的Groq 3 LPX机架则配备256颗LPU,提供128GB片上SRAM和40PB/S推理加速带宽。
XR设备正从娱乐终端跃迁为AI核心载体。随着多模态大模型的推理能力从云端向端侧迁移,XR设备与智能眼镜将具备更强的实时环境感知、需求预测与主动交互能力,不再是被动接收信息的终端,而是能够主动适配用户需求、联动智能家居与智能汽车的智能交互终端。2026年GTC重点强调了AI Agent的发展,年内Agent的智力水平与渗透率有望快速提升,带动B端、C端token调用量增长,而XR设备和眼镜正是Agent实现物理化、场景化的重要载体。以VITURE为代表的厂商在专业科研与消费场景的务实探索,正印证着XR行业正走向技术成熟、生态繁荣的下一阶段。
投资建议:Blackwell与Rubin产品收入有望在2026-2027年维持高速增长,拉动AI产业链需求增长;Vera Rubin POD、LPX机架、Kyber机架等新产品为AI产业链注入发展活力。我们维持电子行业“领先大市”评级,建议关注AI产业链相关公司,例如AI PCB相关的胜宏科技、沪电股份、深南电路,存储相关的兆易创新、德明利、东芯股份,深度参与AI+AR生态建设的整机品牌及其核心供应链相关公司的立讯精密、龙旗科技、蓝思科技等。
风险提示:技术发展不及预期,竞争加剧,新产品需求不及预期,产能释放不及预期,原材料价格波动,贸易摩擦等
1
GTC 2026 黄仁勋演讲回顾
1.1 推理拐点驱动收入增长,Blackwell及Rubin收入有望持续高增
英伟达预期Blackwell与Rubin产品在2025-2027年实现收入约10000亿美元。英伟达全栈技术将AI拓展至各行各业,推理拐点驱动公司收入增长。英伟达在GTC 2025上预期Blackwell与Rubin产品在2025-2026年实现收入约5000亿美元,在GTC 2025之后,公司新增了ANTHROPIC、METASL及其他多个开源项目客户。在GTC 2026上,英伟达预期Blackwell与Rubin产品在2025-2027年实现收入约10000亿美元。考虑英伟达2026财年(日历年20250127-20260125,如未特殊说明均为日历年)公司总收入为2159.38亿美元,公司收入有望在2026-2027年实现高速增长。收入结构上,约60%来自超大规模云服务商,约40%来自NCP、SCC、主权AI、工业及企业级AI等。
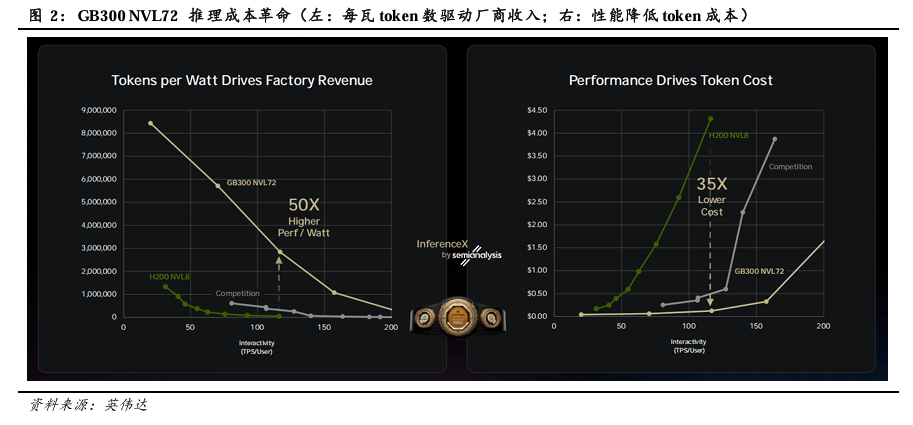
新产品推动推理成本革命。下图左“Tokens per Watt Drives Factory Revenue”所示,随着用户端TPS(Tokens per Second)的增长,同一系统TPW(Tokens per Watt)逐渐下降。下图右“Performance Drives Token Cost”所示,随着用户端TPS的增长,单Token的产出成本逐渐增长。在实现相同TPS的情况下,GB300 NVL72的表现显著优于H200 NVL8及所示竞品。当用户端TPS持续走高时,H200 NVL8及竞品的单瓦产出趋向于0;Token成本则快速上升,大幅高于GB300 NVL72。
1.2 Vera Rubin POD发布,引入LPX机架
1.2.1 Vera Rubin POD
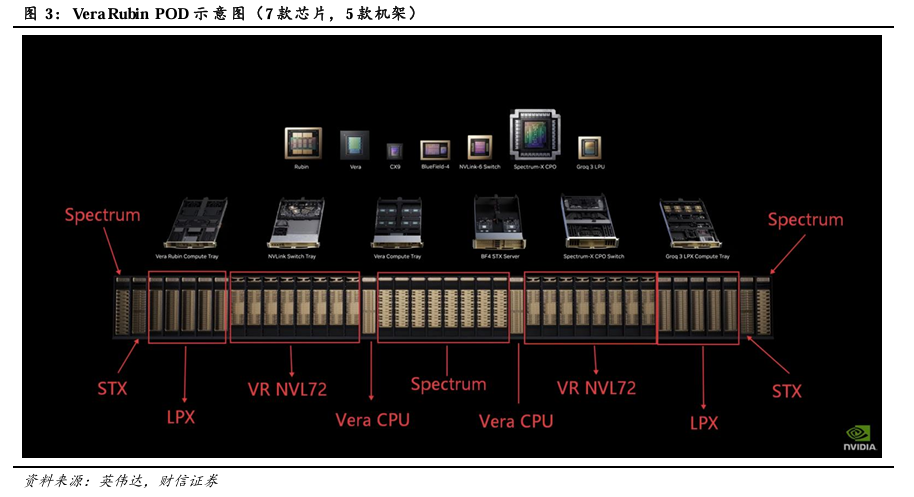
英伟达在GTC 2026上推出Vera Rubin POD,该平台包括7款芯片,5种机架。Vera Rubin POD由16*Vera Rubin NVL72机架+10*Spectrum-6 SPX 以太网机架+10*Groq 3 LPX机架+2*Vera CPU机架+2*BlueField-4 STX存储机架组成。
7款芯片分别为:Vera CPU、Rubin GPU、NVLink 6 交换机、ConnectX-9 SuperNIC、BlueField-4 DPU和NVIDIA Spectrum-6以太网交换机,以及新纳入的NVIDIA Groq 3 LPU。目前该平台搭载的七款新芯片已全面投产。
5种机架分别为:1)Vera Rubin NVL72机架,集成了通过NVLink 6互连的72个Rubin GPU和36个Vera CPU,并配备了ConnectX-9 SuperNIC与BlueField-4 DPU,与Blackwell平台相比,VR NVL72仅需四分之一的GPU即可训练大型混合专家模型,每瓦特推理吞吐量最高可提升10倍,每Token成本为十分之一。2)Vera CPU机架,单机架集成256个Vera CPU,性能表现比传统CPU效率提升1倍,速度提升50%。3)Groq 3 LPX机架,搭载256个LPU处理器,配备128GB片上SRAM和640 TB/S的纵向扩展带宽。LPU专为智能体系统的低延迟和长上下文需求而设计,LPX与Vera Rubin协同部署有望为AI供应商拓展营收机遇。LPX机架预计将在2026年下半年面世。4)BlueField-4 STX存储机架,作为AI原生存储基础设施,可在整个POD中无缝扩展GPU内存。5)Spectrum-6 SPX 以太网机架,专为加速AI工厂“东西向”流量而设计,可灵活配置Spectrum-X以太网交换机或NVIDIA Quantum-X800 InfiniBand 交换机,能够在大规模部署中提供低延迟、高吞吐量的机架间互连。
1.2.2 Groq 3 LPX
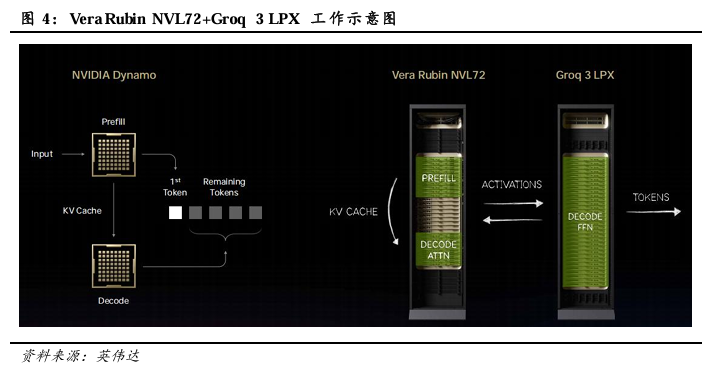
LPX专为智能体系统的低延迟和长上下文需求而设计。NVIDIA Groq 3 LPX 标志着加速计算领域的一个重要里程碑,专为智能体系统的低延迟和长上下文需求而设计,LPX与Vera Rubin 强强联合,汇聚了两款处理器的极致性能,使得每兆瓦的推理吞吐量提升高达 35倍,并为万亿参数模型带来了多达 10 倍的营收机遇。
LPX机架搭载256个LPU处理器。大规模部署时,由LPU组成的集群能够作为一个巨大的单一逻辑处理器运行,提供快速、确定性的推理加速。LPX 机架搭载256 个 LPU 处理器,配备128GB片上 SRAM 和 640 TB/s 的纵向扩展带宽。与Vera Rubin NVL72协同部署时,Rubin GPU 和 LPU 通过协同计算 AI 模型的每一层来生成每一个 Token,从而显著提升解码速度。
为万亿参数模型和百万级 Token 上下文而优化协同设计的 LPX 架构,与Vera Rubin 强强联合,最大限度地提高了功耗、内存和计算方面的效率。每瓦特吞吐量和 Token 性能的提升,开启了超高端、万亿参数、百万上下文推理的新纪元,为所有 AI 提供商拓展了营收机遇。该架构采用全液冷设计,并基于 MGX 基础设施构建,可无缝集成到下一代 Vera Rubin AI 工厂中,预计将在2026年下半年面世。

1.3 需求分类,高性能服务器触及更多市场
1.3.1 Vera Rubin NVL 72
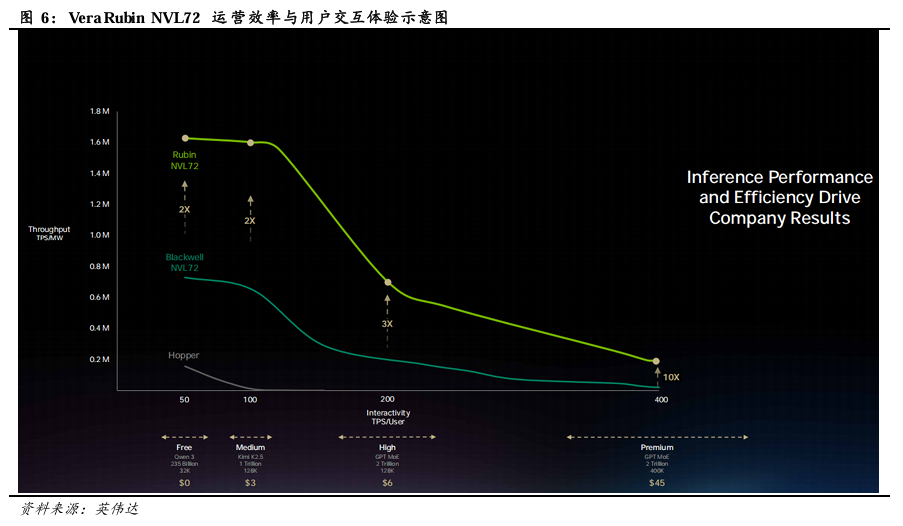
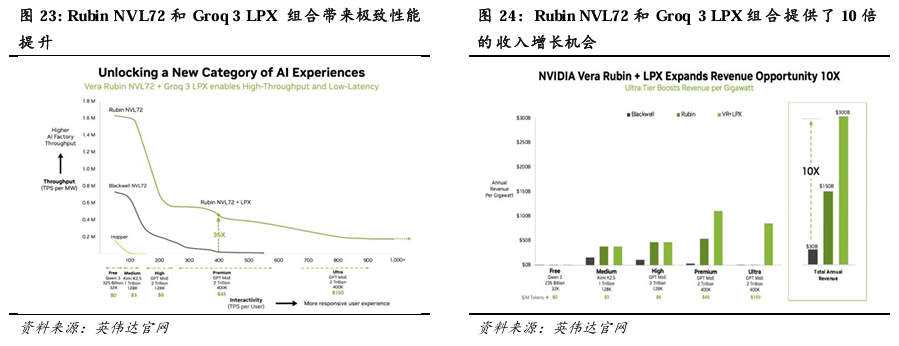
Vera Rubin NVL 72在Premium场景下表现优异。下图纵轴为TPS/MW,反映AI工厂的运营效率;横轴为TPS/User,反映用户实际交互体验或效用。图中英伟达将TPS/User划分为Free、Medium、High、Premium四个层级。1)Free,以极低成本实现大规模用户覆盖,例如Qwen 3(235B参数、32K上下文),50 TPS/User;2)Medium,支持每月约 3 美元的订阅收费,典型如Kimi K2.5(1 Trillion 参数,128K上下文)、100 TPS/User,平衡成本与性能;3)High,支持每月约6美元的收费,典型为2 Trillion参数大模型 + 128K上下文,200 TPS/User,针对更高价值场景;4)Premium,支持每月约45美元的高额收费,典型为 2 Trillion 参数大模型 + 400K 超长上下文,400 TPS/User,面向极致交互、低延迟、深度推理的AI 需求。
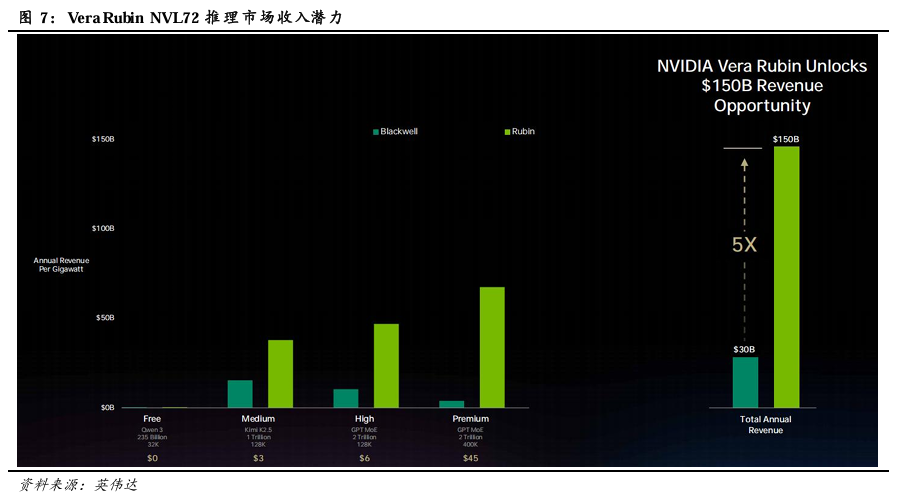
Vera Rubin NVL72创收能力显著优于 Blackwell NVL72。在Free、Medium、High、Premium场景下,Rubin的TPS/MW分别为Blackwell的2倍、2倍、3倍、10倍,Vera Rubin NVL72创收能力显著优于 Blackwell NVL72。Rubin的优势随着TPS/User的增长而放大。得益于此,每 GW(吉瓦)的Vera Rubin平台AI 工厂年营收潜力可达1500 亿美元,相当于 Blackwell的5倍。
1.3.2 Vera Rubin NVL72+LPX
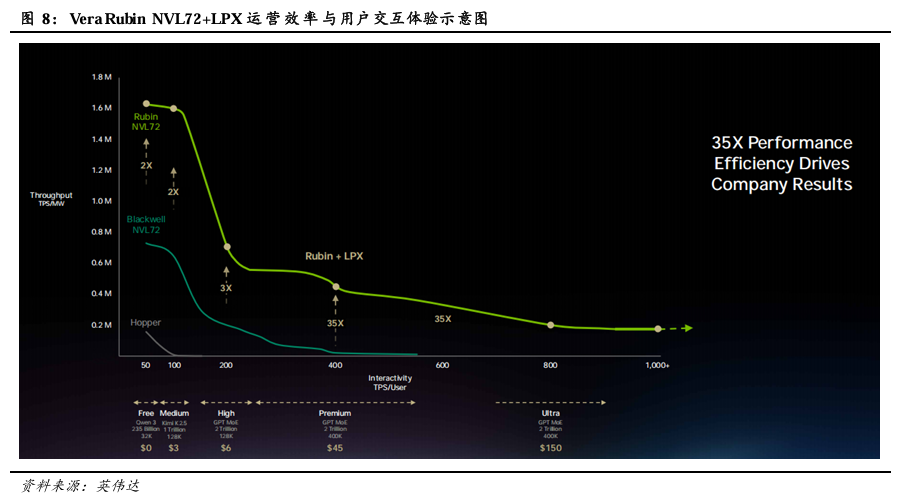
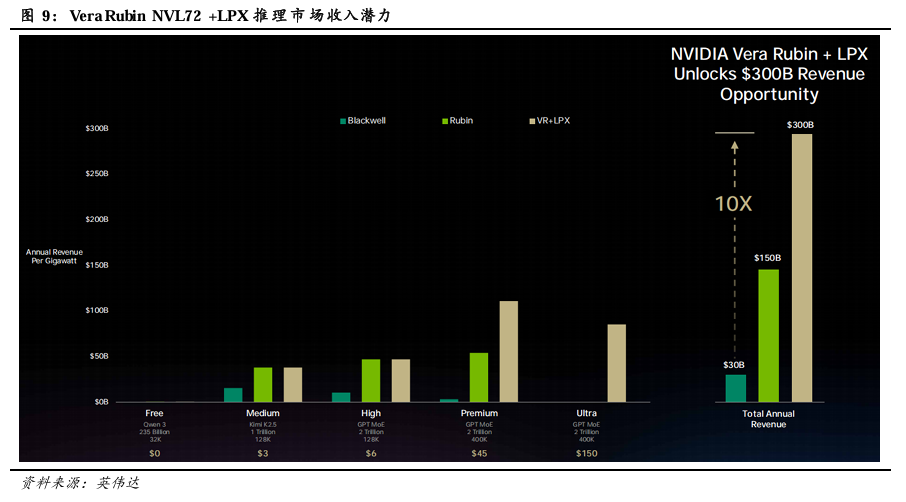
Groq 3 LPX进一步提高Vera Rubin NVL72的TPS/MW表现,并开拓更高TPS/User市场。通过Vera Rubin NVL72与LPX的异构协同架构,GPU提供高带宽 HBM4 内存与强大计算,LPX 则专注 SRAM 驱动的超低延迟解码,系统在高 TPS/user场景下的TPS/MW曲线下降速度放缓。Vera Rubin NVL72+LPX在Premium场景下的TPS/MW表现达到Blackwell的35倍,远超单独使用Rubin时的10倍;并进一步拓展了Ultra(2Trillion 参数大模型 + 400K 超长上下文,达到800 TPS/User)场景,有望实现每月约150美元的收费。得益于此,每 GW(吉瓦)的Vera Rubin NVL72+LPX AI工厂年营收潜力可达3000亿美元,相当于Blackwell的10倍。
1.4 产品路线图
预计Rubin平台于2026年问世,Feynman平台于2028年问世。Rubin平台预计在2026年问世,机架形式有望从Blackwell平台的Oberon NVL72拓展至Oberon NVL72、NVL576,Oberon ETL256,Kyber NVL144。Feynman平台预计在2028年问世,机架形式预计为Oberon NVL72,Oberon ETL256,Kyber NVL144、NVL1152。其中Feynman平台有望使用LP40 NVLink与NVLink 8 CPO 芯片。
2
LPX机架与Kyber Mid-plane拉动PCB需求
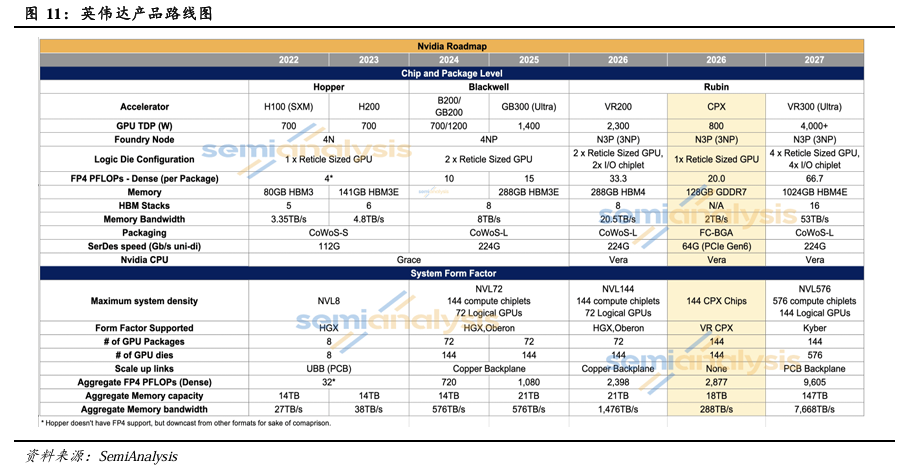
Vera Rubin NVL72与LPX有望在2026年实现量产。下图为GTC 2026前的英伟达产品路线图预期,我们此前预计Vera Rubin 200(VR200)有望率先在2026年下半年实现量产,CPX系列在VR200 之后逐步起量,VR300(Ultra)在2027年实现量产。考虑GTC 2026大会上英伟达未对CPX做进一步介绍,而在Rubin平台中加入Groq 3 LPX,并声明相关芯片均已投入生产。我们调整对英伟达产品路线的预期,预计Vera Rubin NVL72有望率先在2026年实现量产,LPU在2026年下半年逐步起量,Rubin Ultra在2027年实现量产。
Rubin平台取消托架内部线缆,PCB有望承担更多功能。为提高组装效率,解决传统有线缆托盘在装配与运维中的问题,Rubin平台采用无线缆、无软管、无风扇设计的计算托盘架构。随着托盘内部线缆的减少,PCB有望承担更多功能。


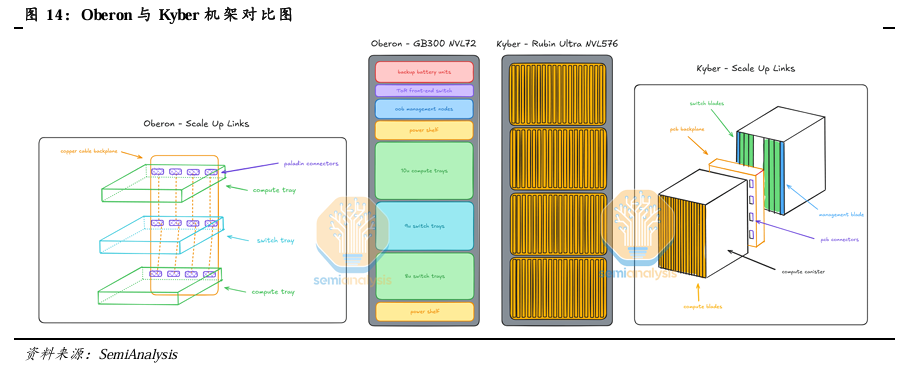
Kyber机架有望使用PCB背板取代铜缆。英伟达在GTC 2025上推出了使用Kyber机架的Rubin Ultra NVL576,Kyber机架与Oberon机架相比,主要有以下区别:
1)计算托盘旋转90度。Kyber将计算托盘旋转90度呈刀片状排列以实现更高的机架密度。
2)单机架芯片数达576个。单个Kyber机架包含四个罐体,每个罐体包含18个计算托盘,每个计算托盘包含2个Rubin Ultra GPU和2个Vera CPU,整个机架含有144个GPU(576个芯片)。
3)PCB背板替代铜缆背板。考虑在更小的空间内布置电缆的难度过高,Kyber将采用PCB背板取代铜缆,作为GPU与机架内NVSwitch之间的扩展链路。机架背面的NVSwitch托盘通过PCB背板的背面连接到计算托盘。
英伟达在GTC 2026大会上展出正交PCB实物。英伟达在GTC 2026上展出了Kyber机架的Rubin Ultra Compute Tray、Mid- plane(中板,正交PCB)及 Switch Tray。下图左侧产品示意图为Rubin Ultra Compute Tray;右侧产品示意图为Mid- plane,共计18列插槽。在Kyber机架中,Compute Tray竖向放置,并通过Mid-plane与另一面的Switch Tray连接。英伟达在GTC 2026上展出Kyber Mid-plane实物,正交PCB技术路线确定性提高。


量价齐升逻辑下,AI PCB市场规模有望迎来高速增长。谷歌、亚马逊、微软、Meta2026年资本开支预计达6550亿美元,同比增长58.44%,有望拉动服务器需求增长。我们假设GPU&ASIC总量同比增长40%,结合单卡对应PCB价值增长50%,预计2026年AI PCB市场规模同比增长110%,实现翻倍增长。
单GPU对应PCB价值情况测算如下:
1)量的因素,PCB增层或者增阶后导致原材料、工艺流程的直接增长,背钻、层压等工艺流程增加,设备、人工成本相应增加。以多层板26层向28层升级为例,简单估算原材料使用量增加7.69%,假设材料、工艺等量的变化推动产品价格上调10%。
2)价的因素,A)存量原材料价格阶梯上涨。根据财联社1月19日资讯,因玻纤布等原材料供应紧张、价格飙升,日本半导体材料厂Resonac宣布自3月1日起调涨铜箔基板(CCL)、黏合胶片等印刷电路板(PCB)材料售价、涨幅达30%以上。Resonac并非近期首家对CCL实施调价的材料厂,2025年底,建滔集团向客户发涨价函,新接单CCL价格全面调涨10%。B)材料升级换代的涨价。AI PCB高频高速需求推动原材料持续升级,树脂、玻布、铜箔整体电性能沿着M7、M8、M9持续升级换代。假设原材料价格变动推动产品价格上调30%。
3)良率的因素,AI PCB新产品更迭&材料、工艺升级,可能降低产线良率,假设良率由92%降低至87%,价格对应上涨5.75%,假设良率因素推动产品价格上调5%。
综合考虑上述因素,单GPU对应PCB价值可由1.00增长至1.50,上涨50%。谷歌、亚马逊、微软、Meta 2026年资本开支预计达6550亿美元,同比增长58.44%,有望拉动服务器需求增长。我们假设GPU&ASIC总量同比增长40%,结合单卡对应PCB价值增长50%,预计2026年AI PCB市场规模同比增长110%,实现翻倍增长。
进一步,我们展望未来的增量:
1)LPX PCB单价有望进一步增长,并实现大规模出货。单价有望进一步增长,LPU计算托盘集成8颗LPU,单个机架搭载32个计算托盘,共256颗LPU,配备128GB片上SRAM和640 TB/s的纵向扩展带宽。LPU机架内需要处理大量数据吞吐且实现极低延迟的通信,有望对PCB层数、材料及工艺提出更高要求,推动PCB价值进一步上涨。LPU有望实现大规模出货,考虑Vera Rubin POD中Vera Rubin NVL72与LPX机架比例为16:10,可得POD中Rubin GPU与LPU比例约为1:2(16*72:10*256),Rubin POD有望拉动LPU大规模出货。
2)Kyber Mid-plane 技术路线确定性提高。GTC 2026大会上展出Kyber机架下的Compute Tray、Mid-plane、Switch Tray,使用PCB进行正交连接的确定性提高,PCB价值有望进一步增长。

3
Rubin平台创新&Agent AI加速渗透,存储需求有望持续释放
3.1 英伟达Rubin平台创新AI存储架构,驱动存储增量跃升
1)推出基于BlueField-4数据处理器的推理上下文记忆存储平台,单机柜存储容量实现跃升。
英伟达Rubin平台在存储配置上较Blackwell平台实现了全方位迭代升级。英伟达在Rubin平台推出了基于BlueField-4数据处理器(DPU)的推理上下文记忆存储平台,该平台创建了一个专用上下文记忆层(G3.5),以弥合高速GPU内存和可扩展共享存储之间的性能差距。从存储配置上看,HBM方面,Rubin NVL72单GPU配备288GB HBM4,单机柜HBM内存达到20.7TB,实现总容量较Blackwell平台提升约1.5倍;DRAM方面, Vera CPU内存作为近端溢出层,单CPU配置1.5TB LPDDR5X,单机柜内LPDDR5X总容量达54TB,总容量较Blackwell平台提升约2.5倍,实现热温冷数据智能流转,进一步突破长上下文场景下的内存瓶颈;NAND方面,Rubin平台在存储架构上,BlueField-4 DPU通过4颗DPU管理150TB内存池直连GPU,为每颗GPU额外拓展16TB上下文空间,这一架构变革直接推动单机柜NAND需求从830TB飙升至近2PB。

2)推出适配低延迟推理需求的LPX机架,创新SRAM增量需求
AI正从生成模型跨入代理模型时代,交互式推理成为核心需求,而这也让AI在生成Token的解码(Decode)阶段面临严重的延迟与存储器带宽瓶颈。随着AI从生成模型跨入代理模型时代,其推理范式正经历根本性转变,从以吞吐量为核心的批处理任务,转向对延迟极度敏感的交互式应用。在这一转型中,大模型生成Token的解码阶段成为关键瓶颈。代理型AI需要将复杂目标拆解为多步推理,每一步的延迟都会累积为用户可感知的端到端响应时间,因此稳定的单Token性能和极低的尾延迟至关重要。解码阶段的挑战在于其自回归特性:模型需顺序生成Token,且每次生成都需读取全部模型权重与历史上下文的KV缓存,导致计算量远小于数据搬运量,核心瓶颈从计算吞吐转向了内存带宽。同时,更长的上下文窗口和更高的用户并发进一步加剧了内存带宽压力,并削弱了传统吞吐优化系统所依赖的批处理效率。因此,专为高吞吐设计的GPU架构在解码阶段面临“内存墙”困境,其片外高带宽存储的访问延迟成为制约响应速度的主因。

英伟达通过整合Groq团队技术,推出专为低延迟推理设计的Groq 3 LPU。Groq 3 LPU单颗芯片集成500MB片上SRAM,虽然与每个Rubin GPU上容量高达288GB的HBM4相比,仅为其1/500。但SRAM提供高达150TB/s的带宽,较HBM4 22TB/s带宽提升近7倍,可满足需要极致低延迟的Token生成任务。在英伟达的LPX机架级设置中,8颗LPU芯片组成一个计算托盘,基于Groq 3 LPU芯片的Groq 3 LPX机架则配备256颗LPU,提供128GB片上SRAM和40PB/S推理加速带宽。
LPU与GPU在分工配比上,英伟达的策略是让Rubin GPU负责预填充阶段,让Groq LPU负责解码阶段。由于LPU本身的存储器容量无法容纳Vera Rubin等级的庞大参数与KV Cache。NVIDIA因此于本次GTC提出“解耦合推理(Disaggregated Inference)”架构,通过名为Dynamo的AI工厂作业系统,将推理流水线一分为二:处理代理型AI时,需进行大量数学运算并储存庞大KV Cache的Pre-fill、Attention运算阶段,交由具备极高吞吐量与巨量存储器的Vera Rubin执行。而受限于带宽且对延迟极度敏感的译码与Token生成阶段,则直接卸载至扩充了巨量存储器的LPU机柜上。
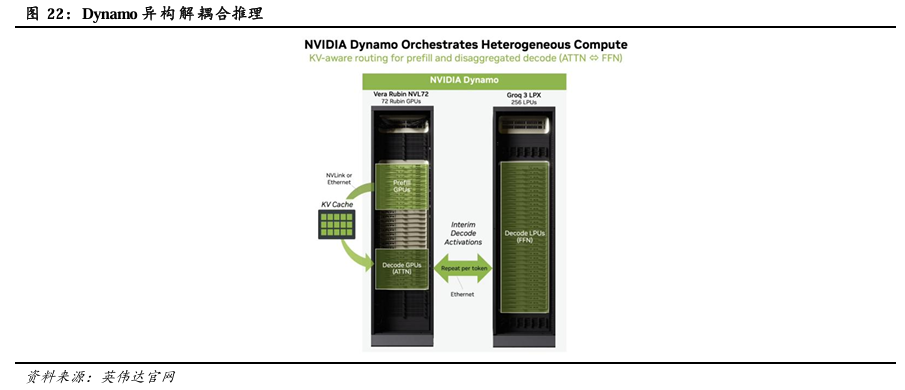
Rubin GPU和Groq LPX异构架构带来了推理性能及经济效益的极致提升。根据英伟达官方基准测试,以运行2万亿参数规模的MoE模型为例,Rubin GPU与Groq LPU组合与NVIDIA GB200 NVL72方案相比,推理吞吐量每兆瓦提升高达35倍。从经济效益来看,借助Vera Rubin平台,AI工厂每兆瓦可获得比GB200 NVL72多达5倍的收入,而将Vera Rubin的NVL72与LPX配合使用,其营收潜力可提升至10倍。
3.2 Agent AI应用驱动Token消耗激增,存储数据底座需求有望持续释放
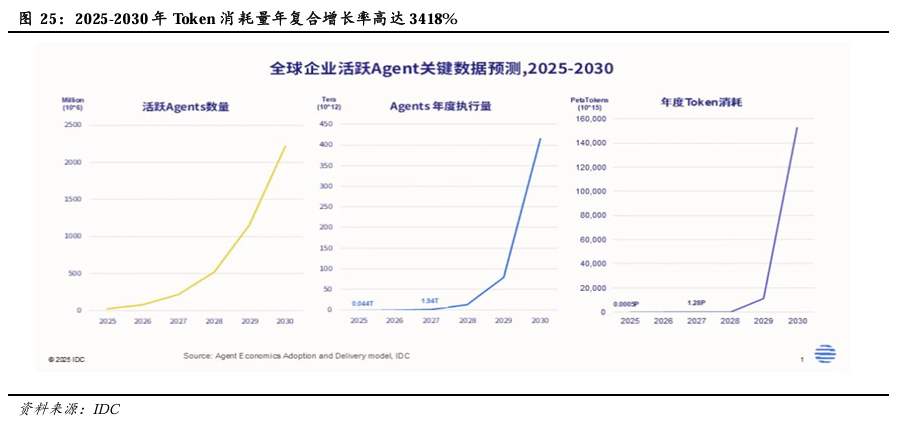
Agent AI的Token消耗量较传统AI应用激增,预计将推动算力需求实现指数级增长。Agent AI 以ReAct推理-行动闭环自主执行复杂任务,推理过程中需拆解目标、多轮调用工具、自我校验与试错,单任务触发多次模型推理,因而其Token 消耗相较于传统AI应用“一问一答”的脉冲式交互,呈叠加式增长;同时,Agent 必须携带完整历史上下文进行每轮推理,上下文随交互轮次指数膨胀,形成“滚雪球”式Token消耗;且其内置心跳/定时任务机制实现 7×24 小时后台静默运行,无用户交互也持续产生隐性Token消耗。此外,Agent 需加载庞大的系统提示词与工具定义,同时多个子 Agent 并行、工具链级联触发进一步放大消耗,最终使单任务 Token 消耗较传统AI大幅跃升。以OpenClaw为例,一个重度“养虾”用户,日均消耗Token在3000万至1亿之间。作为对比,一个普通ChatGPT用户即使天天聊天,月消耗也不过百万级。根据IDC预测,未来五年,全球Agent生态将经历一场指数级的扩张,到2030年,全球活跃AI智能体将达22.16亿,年度Token消耗量将从2025年的0.0005 Peta Tokens飙升至15.3万Peta Tokens,年复合增长率高达3418%。
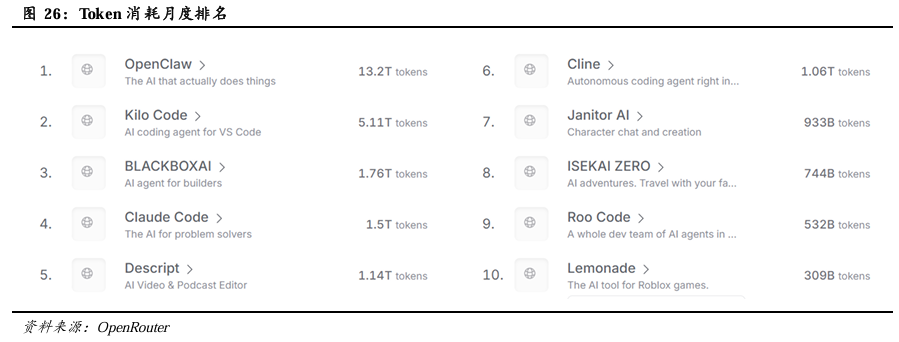
OpenClaw的发布实现了大模型从“对话式AI”到“执行型AI”的范式跃迁,加速Agent AI生态破圈。OpenClaw本地优先架构、跨平台操控、插件化技能支持数千种扩展能力,以及其具备长期记忆和主动任务执行能力等创新设计,使其做到能真正接管用户电脑、自动调用工具完成复杂任务,像一个24小时在线的“数字员工”,精准击中了市场对“能干活AI”的刚需,因而一经发布2026年初即实现爆火,迅速从极客圈破圈至全民热潮,跃升为全球范围内Token消耗最高的应用。根据AI模型聚合平台OpenRouter数据,截至2026年3月21日,OpenClaw Token当月消耗量达到13.2万亿,成为该平台Token消耗最高的应用。
国产厂商则凭借极致的成本优势及政策端的支持,实现Token调用规模对海外模型厂商的追赶。国产模型厂商凭借国内极致的电价等成本优势,可实现API调用价格大幅低于海外同类产品;同时深圳、无锡等各地相继出台“养龙虾”支持政策,国产模型调用量快速增长,并逐步实现对海外模型厂商的追赶。根据国家数据局,2024 年初中国日均Token的消耗量仅为1000亿,而2025年6月底日均Token消耗量已突破30万亿,1年半时间增长了300多倍。根据OpenRouter数据,2026年3月9日至3月15日,排名前十榜单中的中国大模型的周调用总量达到 4.6万亿Token,而美国大模型的周调用量为 2.3万亿Token,中国大模型的周调用总量实现连续三周大模型调用规模超过美国。
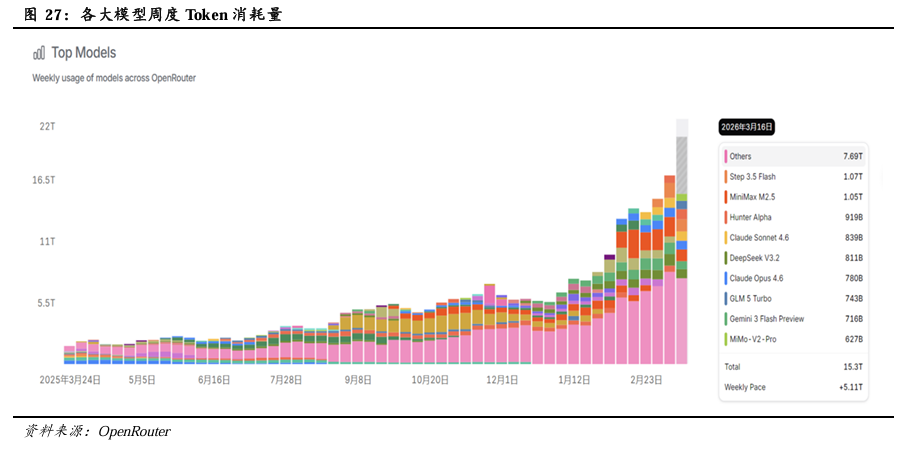
随着Agent AI应用场景不断拓展、落地规模持续扩大,Token消耗的激增态势预计将长期延续,存储作为支撑其稳定运行的核心基础设施,其扩容、升级及优化需求有望持续释放,有望成为AI产业进程中的核心需求增长点。
4
XR升维:从娱乐终端跃迁为AI核心载体,应用场景持续拓宽
XR设备正从单一的沉浸式娱乐终端,升级为承接并延展AI能力的交互载体。随着人工智能技术的纵深发展,XR设备已不再局限于游戏、观影等娱乐场景,而是逐步成为连接虚拟与现实、承载AI交互的关键载体,推动行业发展迈入全新阶段。2026年英伟达GTC大会上,VITURE作为行业内持续探索XR+AI的代表企业参展,集中展示了XR+AI在科研、消费、文旅、医疗等多元场景的落地突破,清晰印证了AI眼镜已进入B端专业赋能与C端体验升级双线并行、协同发展的新阶段。作为此次唯一参展且与英伟达官方合作的XR智能眼镜品牌,VITURE重点展示了其携手英伟达及斯坦福大学(Stanford University)Cong Lab共同推出的XR-AI Lab Automation解决方案,以及搭载于英伟达云游戏服务GeForce NOW的Immersive 3D沉浸式云游戏体验。此外,备受瞩目的VITURE年度旗舰新品Beast也同步亮相,全面彰显了其在消费级与专业级XR领域的领先布局与技术实力。
专业级应用实现关键突破,XR+AI迈向高壁垒的科研场景。当前,各类通用型AI助手已广泛融入人们的日常生活,在信息获取、决策辅助、日常陪伴等场景中发挥着重要作用。然而,面对科研领域高度专业化、流程复杂化、操作精密化的严苛要求,传统AI技术难以满足动态场景理解、实时专业指导、关键决策参与等核心需求,导致其应用落地长期受限,至今仍面临诸多挑战。VITURE在2026 GTC现场推出的XR-AI Lab Automation实验室自动化解决方案,率先突破技术瓶颈,将XR+AI融合技术落地高精度科研场景,将XR设备的应用边界拓展至实验室科研级别。该方案以VITURE Luma Ultra XR智能眼镜为核心硬件载体,搭配VITURE Pro颈环与后台AI系统深度响应,协同机械臂作业,为AI赋予“第一视角”,在科研场景下实现“所见即所识”——实时呈现可视化数据、指导实验操作、分析关键参数并全程追踪项目进度,可协助科学家完成基因编辑级别的精密实验,让“Co-Scientist”人机协作科学家的概念变为现实。目前,该方案已可以应用于免疫疗法、干细胞工程及材料科学等研究领域,显著提升了科研工作的精准度与效率。

XR+AI在科研场景应用成效显著,实现时间、成本与培训周期三重颠覆性优化。斯坦福大学医学院Cong教授表示,通过XR+AI的融合,可将原本需要数年能完成的科研工作缩短至数周,数百万美元量级的实验成本降至数千美元,复杂的实验培训周期也从数月缩减至数天,其降本增效成果远超传统科研模式。相较于普通娱乐或消费场景,科研环节对设备稳定性、数据精准度、实时交互效率有着极为严苛的要求。传统科研模式依赖多台设备切换、频繁调整视线,极易造成效率损耗与认知中断,进而影响实验进度与精准度;而VITURE XR智能眼镜可将实验流程、数据提示、操作指引直接叠加在科研人员视野中,同时承担信息显示终端与AI交互核心的双重角色,有效规避了传统科研模式的弊端。此次VITURE、英伟达与斯坦福大学Cong Lab的三方合作,标志着XR眼镜突破消费场景局限,成功进入高价值、高壁垒的专业化工作场景。

Immersive 3D技术颠覆内容生态,AI眼镜消费级体验迎来突破。在消费级层面,AI与云计算的深度融合正在重塑XR的内容生态与体验边界,打破算力与内容供给的瓶颈。使用XR眼镜体验3D游戏时,设备自身的算力与内容生态往往成为限制因素;而高质量原生3D内容生产成本居高不下,长期制约着XR设备的体验升级。VITURE在GTC现场全球首次展示了其旗舰级AI功能Immersive 3D搭载于英伟达GeForce NOW云游戏服务的沉浸式游戏体验。Immersive 3D功能依托自研算法、生成式AI能力与云计算技术的支持,能够将传统2D画面实时转化为具备空间深度感的3D视觉效果,用户无需依赖高性能本地设备。这不仅为激活存量现有资源提供了全新路径,也显著降低了用户获取沉浸式内容的门槛,推动XR内容供给从“高成本稀缺创造”走向“低成本普惠转化”。
Immersive 3D技术正推动XR设备从单一娱乐场景向全场景普惠方向拓展。VITURE持续推进Immersive 3D技术在多元商业与民生场景的落地应用:在文旅领域,VITURE携手天坛公园打造沉浸式XR游览体验,实现“时空穿越”式文旅互动,即便处于户外强光环境,也能为游客带来影院级高清视听感受;在医疗领域,VITURE XR智能眼镜可作为低视力群体的视觉辅助工具,帮助其获取更高清晰度的影像内容,提升生活便利性。这些多元化落地实践充分表明,XR智能眼镜正逐步升级为覆盖日常娱乐、生活辅助、专业增效与社会关怀的全能型交互终端。
市场与资本双重认可下,VITURE确立全球高端XR眼镜领军地位。继2025年9月融资1亿美元后,VITURE于2026年2月再次完成1亿美元融资,半年内融资总额超2亿美元。据IDC报告显示,得益于VITURE Luma系列XR眼镜的上市,VITURE以近三分之一的市场份额稳居2025年第三季度美国AR市场销量冠军,并成为首个进驻美国百思买(Best Buy)的XR品牌。亚马逊官方数据显示,VITURE Luma系列在多个市场表现亮眼,包揽日本、德国、法国、西班牙、意大利、沙特阿拉伯等欧亚10国亚马逊AR眼镜销量榜首。2026 GTC大会亮相的年度旗舰新品VITURE Beast XR眼镜,进一步强化了其产品竞争力,该产品搭载58°超大视场角、内置原生3DoF、120Hz高刷新率、1250尼特超高亮度以及9档无极电致变色等硬核配置,将VITURE长期自研的SpaceWalker软件能力发挥到极致,实现了iPhone与Android手机端无缝多屏体验、电脑端低延迟多屏扩展等创新功能,覆盖游戏观影、移动办公等多场景需求,进一步完善了VITURE高端产品矩阵,强化了其在消费级与专业级市场的双线布局。


AI+XR推动XR行业从娱乐终端转向下一代通用计算入口。AI技术的融入重新定义了XR设备的用途,推动行业从沉浸式娱乐终端向下一代计算入口加速转型。根据洛图科技(RUNTO)的数据显示,2025年全球XR设备与智能眼镜的合并出货量超过1200万台,市场呈现出明显的结构性分化:XR设备出货量为608万台,同比下降16.8%;智能眼镜(包含AR眼镜)市场出货量为681万台,同比大涨156%,轻量化智能眼镜成为行业增长的核心驱动力。洛图科技(RUNTO)预测,2026年全球XR设备出货量将达到705万台,同比增长16.0%;智能眼镜出货量将达到1165万台,同比增长71.1%。中国市场受益于国家补贴政策的倾斜,2026年XR设备(VR/MR/AR)销量有望达到110万台,同比上涨58.8%,增长的核心动力仍来自AR设备;智能眼镜整体销量有望突破320万台,同比增长120%。随着多模态大模型的推理能力从云端向端侧迁移,XR设备与智能眼镜将具备更强的实时环境感知、需求预测与主动交互能力,不再是被动接收信息的终端,而是能够主动适配用户需求、联动智能家居与智能汽车的智能交互终端。2026年GTC重点强调了AI Agent的发展,年内Agent的智力水平与渗透率有望快速提升,带动B端、C端token调用量增长,而XR设备和眼镜正是Agent实现物理化、场景化的重要载体。以VITURE为代表的厂商在专业科研与消费场景的务实探索,正印证着XR行业正走向技术成熟、生态繁荣的下一阶段。
5
投资建议
Blackwell与Rubin产品收入有望在2026-2027年维持高速增长,拉动AI产业链需求增长;Vera Rubin POD、LPX机架、Kyber机架等新产品为AI产业链注入发展活力。我们维持电子行业“领先大市”评级,建议关注AI产业链相关公司,例如AI PCB相关的胜宏科技、沪电股份、深南电路,存储相关的兆易创新、德明利、东芯股份,深度参与AI+AR生态建设的整机品牌及其核心供应链相关公司的立讯精密、龙旗科技、蓝思科技等。
6
技术发展不及预期,竞争加剧,新产品需求不及预期,产能释放不及预期,原材料价格波动,贸易摩擦等。

本订阅号不是财信证券研究报告的发布平台,所载内容均来自财信证券已正式发布的研究报告或对报告进行的跟踪与解读,订阅者若使用所载资料,有可能会因缺乏对完整报告的了解而对其中关键假设、评级、目标价等内容产生误解。提请订阅者参阅财信证券已发布的完整证券研究报告,仔细阅读其所附各项声明、信息披露事项及风险提示,关注相关的分析、预测能够成立的关键假设条件,关注投资评级和证券目标价格的预测时间周期,并准确理解投资评级的含义。
通过本订阅号发布的内容仅供财信证券股份有限公司(下称“财信证券”)研究服务客户参考,因本订阅号暂时无法设置访问限制,根据《证券期货投资者适当性管理办法》的要求,若您并非财信证券的研究服务客户,为控制投资风险,应首先联系财信证券研究发展中心,完成投资者适当性匹配,并充分了解该项服务的性质、特点、使用的注意事项以及若不当使用可能会带来的风险或损失,在此之前,请您请取消关注,请勿订阅、接收或使用本订阅号中的任何信息。对由此给您造成的不便表示诚挚歉意,感谢您的理解与配合!
财信证券研究发展中心分为宏观策略、综合金融、大制造、大消费、大周期和TMT等研究团队,研究领域涵盖市场策略、行业研究、公司研究,以及基金、债券研究等,已基本完成A股主要行业及重点上市公司的全覆盖。研究报告除自有研究业务平台及微信公众号外,授权同花顺、Wind、东方财富、讯兔科技、湖南日报、潇湘晨报、红网、上海证券报、中国证券报和朝阳永续刊载或转发。未经授权刊载或转载的,财信证券将追究其相应的法律责任。
网址:stock.hnchasing.com
地址:长沙市岳麓区茶子山东路112号湘江财富金融中心B座25楼
邮编:410005
电话:0731-84403360
传真:0731-84403438
>>>查看更多:股市要闻
