重要提示
本微信号推送的内容仅面向财通证券客户中符合《证券期货投资者适当性管理办法》规定的专业投资者。本微信号建设受限于难以设置访问权限,为避免不当使用所载内容可能带来的风险,若您并非专业投资者,请勿订阅、转载或使用本微信号的信息。
摘要
投资要点
LPU为新一代面向大模型推理阶段的芯片,核心为TSP架构。LPU是专为顺序处理的计算密集型任务设计的新型芯片架构,核心在于TSP架构,包含五大功能模块,将经典的处理器五级流水线拆散在整个芯片内,进而消除了硬件的复杂性,使指令执行顺序和时间具有确定性。在TSP架构下,编译器可以直接访问并精确控制芯片的底层硬件状态,实现了软件定义硬件。
LPU可缩短大模型推理过程中的延迟,提高用户体验感。大模型在推理过程中会存在延迟,延迟与用户体验感精密挂钩,大模型推理过程中的延迟主要在Decode阶段,核心瓶颈在于内存带宽。LPU具备更快的内存带宽,可缩短大模型推理过程中的延迟。同时,基于LPU的大模型不仅具有更快的推理速度,还可以提供更具性价比的价格,可进一步提高用户体验感。
LPU具备广阔的潜在发展空间,已步入量产初期。目前Tokens的消耗量大幅增长,2024年初我国日均Token的消耗量为1000亿,2026年2月主流大模型合计日均Token消耗已到180万亿级别,Tokens消耗量快速增长,带动推理芯片市场规模的高增长。LPU可降低大模型推理的延迟,我们认为LPU有望在推理芯片市场中逐步渗透,具有高成长性的市场空间。目前LPU已步入量产初期,放量在即。
投资建议
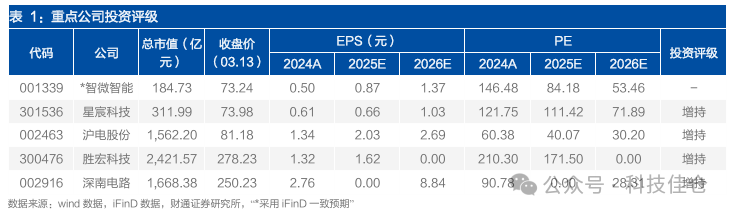
我们认为LPU受益于低推理延时的优异表现,有望实现快速渗透,我们看好LPU的高成长性及LPU以机柜出货时带来的PCB机会,建议关注:智微智能(参股元川微)、星宸科技(多轮增资元川微)、沪电股份(英伟达PCB供应商)、胜宏科技(英伟达PCB供应商)、深南电路。
风险提示
AI技术迭代不及预期的风险
大模型发展不及预期的风险
LPU行业发展不及预期的风险
内容目录
1 LPU面向大模型推理阶段,TSP架构为核心
1.1 LPU是一款用于大模型推理阶段的定制芯片
1.2 LPU核心在于TSP架构,指令执行顺序和时间具有确定性
1.3 软件定义硬件,编译器定义芯片行为
1.4 单节点内Fullmesh拓扑,单机柜内Dragonfly拓扑
2 LPU可缩短大模型推理过程中的延迟,提高用户体验感
2.1 大模型推理延迟与用户使用体验感紧密挂钩,延迟主要发生在Decode阶段
2.1.1 大模型推理过程分为Prefill和Decoding两个阶段
2.1.2 延迟/吞吐/利用率为衡量大模型推理性能的指标,延迟与用户使用体验感紧密挂钩
2.1.3 大模型推理过程中的延迟主要在Decode阶段,核心瓶颈在于内存带宽
2.2 LPU具备更快的内存带宽,可缩短大模型推理过程中的延迟
2.2.1 LPU采用SRAM作为存储介质,解决大模型推理阶段面临的内存带宽受限问题
2.2.2 基于LPU的大模型具有更快的推理速度和更具性价比的价格
3 LPU具备广阔潜在发展空间,已步入量产初期
3.1 Tokens消耗量大幅增长带动推理芯片市场规模高增长,LPU具备广阔潜在发展空间
3.2 海外已进入量产初期,国内已推出LPU产品
4 投资建议
5 风险提示
图表目录
图1:TPU是一款用于大模型推理阶段的定制芯片
图2:LPU集成了230MB容量的SRAM,片上内存带宽高达80TB/s
图3:整体芯片具有五大功能切片
图4:ICU排布于芯片下方,MXM、SXM、MEM功能切片呈双侧对称分布
图5:传统的MultiCore架构中,每个PE都是一个完整的多级流水线架构
图6:TSP将经典的处理器五级流水线拆散在了整个芯片内
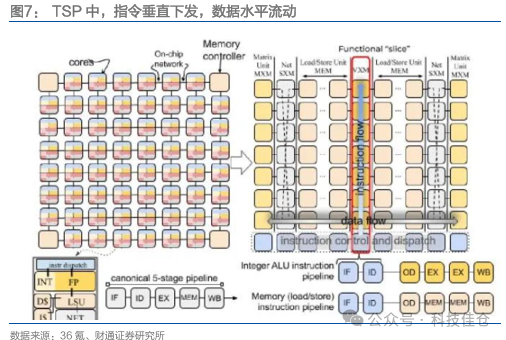
图7:TSP中,指令垂直下发,数据水平流动
图8:Groq系统架构形式一览
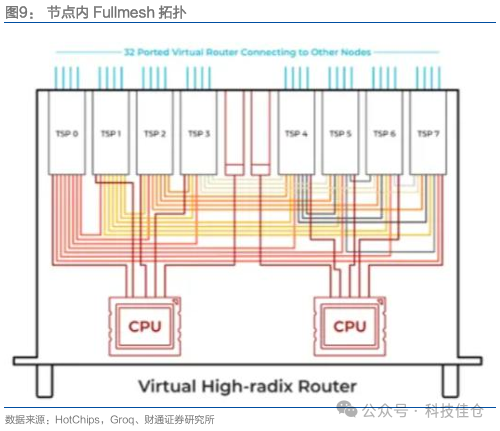
图9:节点内Fullmesh拓扑
图10:机柜内Dragonfly拓扑
图11:大模型进行推理时可分为Prefill和Decode阶段
图12:大模型推理过程中的情况举例
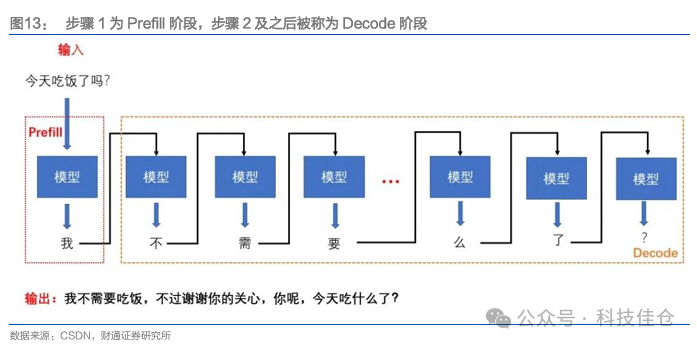
图13:步骤1为Prefill阶段,步骤2及之后被称为Decode阶段
图14:基于LPU的大模型具有更快的推理速度和更具性价比的价格
图15:Groq的大模型吞吐量速度超350Token/s,远超其他大模型厂商
图16:全球推理AI芯片市场规模2031年有望达到690.1亿美元
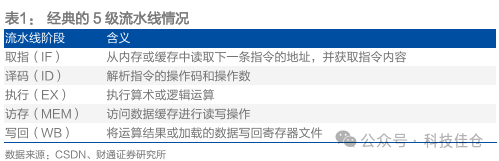
表1:经典的5级流水线情况
表2:CPU设计带来的不确定性
表3:编译器可从指令调度、数据流控制、存储管理三个维度定义芯片行为
表4:Groq LPU的系统架构构成
表5:上述例子中每一步的输入Prompt与输出展示
表6:引入KVCache技术后每一步的输入与输出展示
表7:延迟指标主要衡量的是从请求提出到获得响应所需的时间
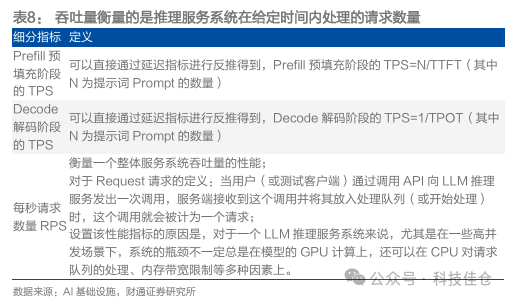
表8:吞吐量衡量的是推理服务系统在给定时间内处理的请求数量
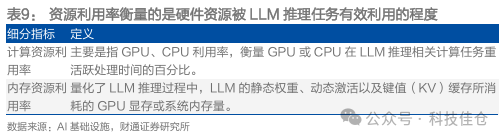
表9:资源利用率衡量的是硬件资源被LLM推理任务有效利用的程度
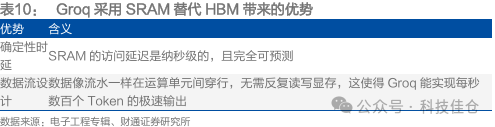
表10:Groq采用SRAM替代HBM带来的优势
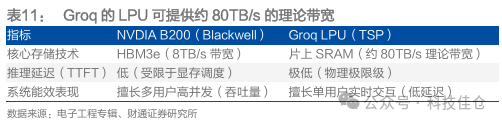
表11:Groq的LPU可提供约80TB/s的理论带宽
表12:Groq第二代LPU已实现量产
正文
1
LPU面向大模型推理阶段,TSP架构为核心
1.1LPU是一款用于大模型推理阶段的定制芯片
LPU是一款专用于大模型推理阶段的定制芯片。LPU(Language Processing Unit,语言处理单元)是专为顺序处理的计算密集型任务设计新型芯片架构,其核心目标是通过架构创新优化语言模型的推理效率。LPU由Groq公司推出,Groq成立于2016年,LPU旨在用于大模型推理阶段,LPU是唯一一款为开发者提供所需性能且成本不影响开发者的定制推理芯片。

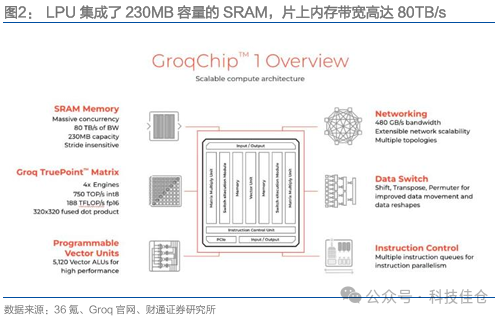
LPU采用14nm制程工艺,集成SRAM,可提供80TB/s的片上内存带宽。LPU没有采用尖端制程工艺,选择了14nm制程,集成了230MB容量的SRAM来替代DRAM,以保证内存带宽,其片上内存带宽高达80TB/s。在算力层面,Groq芯片的整型(8位)运算速度为750TOPs,浮点(16位)运算速度则为188TFLOPs。
1.2 LPU核心在于TSP架构,指令执行顺序和时间具有确定性
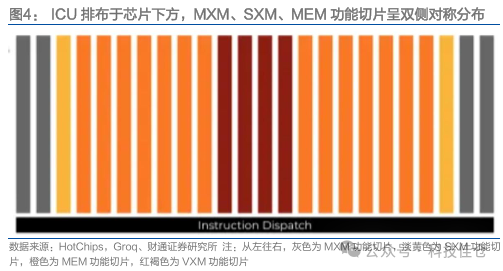
LPU核心TSP架构,包含五大功能切片。整体芯片架构包含五大功能切片,MXM用于执行矩阵运算,SXM用于对矢量进行移位和旋转操作,MEM用于内存读/写运算,VXM用于向量上的算术运算,ICU为指令控制单元,负责获取和调度指令并在其他切片上执行。从整体来看,ICU排布于芯片下方,MXM、SXM、MEM功能切片以VXM功能切片为中心呈双侧对称分布。

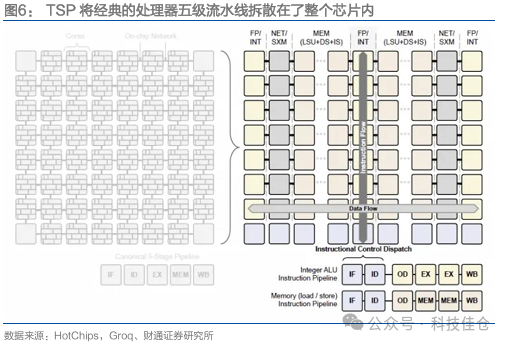
相较于传统多核处理器,TSP将经典的处理器五级流水线拆散在整个芯片内。在传统的MultiCore架构中,每个PE都是一个完整的多级流水线架构配置了独立的指令译码/派发器件和独立的Cache层次化结构;在TSP微架构上,对传统的多核处理器微架构进行了重组。经典的处理器五级流水线被拆散在了整个芯片内。

指令垂直下发,数据水平流动。相较于传统多核处理器,Groq整个芯片构建了独立的ICU(Instruction Control Units)用于取指和译码,整个芯片被水平地划分为多个功能切片。在每个时钟周期中,ICU会向下方对应的功能切片垂直地、同步地广播指令,这种执行方式类似于SIMD,所有位于同一垂直列上的FU在同一时刻执行由顶部ICU发出的指令;数据从一个功能切片产生,变成一个“流”,水平地流向下游的功能切片进行运算,计算结果再继续以流的形式向下游传递,或者被写回MEM单元。
TSP架构消除了硬件的复杂性,指令执行顺序和时间具有确定性。基于微架构的设计,在CPU和GPU上执行指令是不确定的,无法保证特定指令何时执行、完成需要多长时间以及何时提供结果。CPU中指令执行的顺序和时间不确定且难以推理,而GPU还有其他一些非确定性因素,包括缓存、共享和全局内存、动态资源分区等。非确定性带来的问题是,很难推理程序的性能,也很难保证最坏情况下的性能限制。相较于CPU和GPU,Groq的TSP没有不确定的行为,这消除了硬件的复杂性,使编译器能获得更大的权利,精确调度和控制指令的执行,保证对程序性能的限制。

1.3 软件定义硬件,编译器定义芯片行为
软件定义硬件,编译器可以直接访问并精确控制芯片的底层硬件状态。TSP的设计人员简化了硬件,编译器需要精确地调度指令和数据流,以正确执行给定的程序,并以最有效的方式执行;同时,由于TSP硬件中没有非确定性行为,因此编译器可以准确了解每条指令的延迟,以及程序中的数据流,编译器的后端可以跟踪片上任何流的位置和使用时间,称为软件定义硬件。

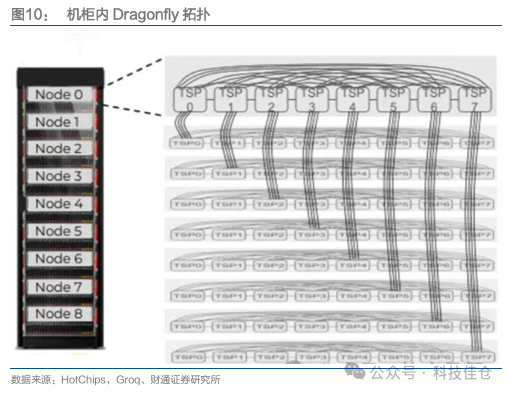
1.4 单节点内Fullmesh拓扑,单机柜内Dragonfly拓扑
单节点包含8个GroqChip,一个机柜包含9个GroqNode。据Groq提供的整体端到端实时AI和HPC解决方案,主要是四部分:GroqChip、GroqChip、GroqNode、GroqRack。

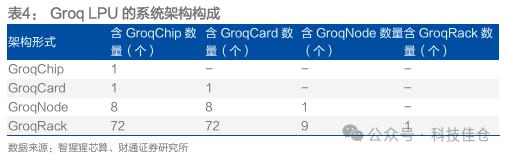
节点内Fullmesh拓扑,机柜内Dragonfly拓扑。在Node中,8张GroqCard通过线缆构成一个Fullmesh的结构,每张卡顶部有7个互联接口,通过线缆链接到其他7张卡;每张GroqCard背板位置有4个接口用于链接其他Node,并构成一个Dragonfly拓扑。
2
LPU可缩短大模型推理过程中的延迟,提高用户体验感
2.1 大模型推理延迟与用户使用体验感紧密挂钩,延迟主要发生在Decode阶段
2.1.1 大模型推理过程分为Prefill和Decoding两个阶段
大模型推理过程可分为Prefill和Decoding两个阶段。目前主流的大模型采用的架构是Decode-Only架构,在使用Decode-Only架构的大模型进行推理时,整个推理过程主要分为两个阶段:一个是Prefill阶段,一个是Decode阶段。
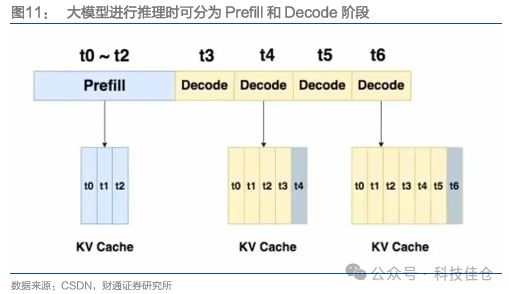
Prefill阶段:大模型接收到用户输入的问题(Prompt)后,生成回答中的第一个单词(Token)的阶段;Decode阶段:大模型根据输出的第一个单词(Token)的回答后继续进行后续预测输出的阶段。
在大模型推理过程中,大模型会不断根据输入的Prompt持续输出Token。从大模型与使用者进行交互并生成回答的过程中,使用者会先将问题输入给大模型,对于大模型而言,这个问题叫做“Prompt”,也就是提示词;大模型接收到提示词后,便开始执行推理过程:大模型会根据“Prompt”来回答第一个回答的单词,随后会根据输出的第一个回答的单词来不断地预测后一个回答的单词,直到把需要回答的单词全部生成完。
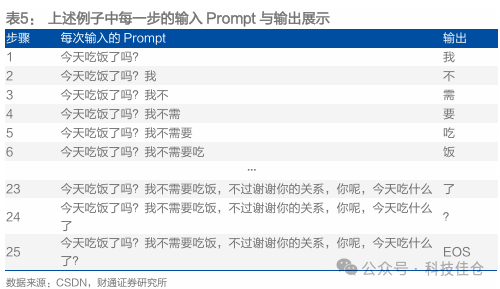
Prefill阶段和Decode阶段具有共通点。两个阶段在大模型运行的过程是一样的,不一样的是大模型接收到的输入不一样。以下图场景为例,对于大模型来说,第一次的输入(Prefill阶段的输入)是“今天吃饭了吗”这句话,模型的输出是回答中的第一个词,也就是“我”,随后将得到的输出和输入合并成一个新的Prompt输入给大模型,大模型输出“不”,依次类推,直到满足一定的条件(如输出最后一个字符),大模型停止输出,模型回答完毕。

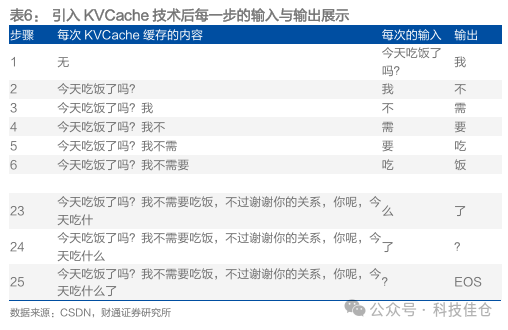
引入KVCache技术减轻计算量。在每个步骤输入的Prompt存在大量的重复单词,为减轻重复单词带来的计算量,引入了KVCache技术,KVCache技术就是把上一步骤已经计算过的单词进行缓存,方便在下一步骤的时候直接使用,并且把新的输入加到已经缓存好的单词的末尾就可以了。
2.1.2 延迟/吞吐/利用率为衡量大模型推理性能的指标,延迟与用户使用体验感紧密挂钩
大模型在推理过程中有一些重要的性能指标的定义和含义,对于这些指标,大致可分为三类:延迟Latency、吞吐Throughput、利用率Utilization。
延迟Latency
延迟Latency指标衡量从请求提交(提出Prompt)到获得响应所需的时间,对于实时交互式应用至关重要。可细化分为:1.首Token生成时间/延迟(Time to First Token,TTFT),2.逐个Token生成时间(Time Per Output Token, TPOT),3.端到端请求时间/延迟(End-to-End Request Latency)。因为延迟决定了用户感知模型生成输出的速度,与用户使用体验感紧密挂钩。

吞吐量Throughput
吞吐量Throughput指标衡量推理服务系统在给定时间内处理的请求或令牌数量,可以细化分为每秒Token数(Tokens Per Second,TPS,又可以继续细分为Prefill预填充阶段的TPS和Decode解码阶段的TPS)、每秒请求数量(Requests Per Second,RPS)。
资源利用率Utilization
资源利用率指衡量硬件资源被LLM推理任务有效利用的程度。其中可以大致分为计算资源利用率、内存资源利用率。
2.1.3 大模型推理过程中的延迟主要在Decode阶段,核心瓶颈在于内存带宽
Prefill阶段和Decode阶段对于资源的需求不同。1)Prefill阶段:大模型一次性对Prompt中所有Token进行计算QKV,由于不同Token的计算是独立的,因此该过程可以并行,在Attention部分,计算得到的QKV进一步计算出Output矩阵,再经过后续的FFN层和解码得到首字母Token。因此Prefill阶段存在大量矩阵乘法和Attention计算,GPU的算力利用率很高,但内存带宽压力较小。Prefill是典型的Compute-bound阶段;2)Decode阶段:计算过程可以复用Prefill阶段的KV结果,也可以复用Decode阶段已经产生的KV结果,在KVCache技术下,对于Q矩阵,每次需要计算的只是Q的最后一行q,计算关于qKV的attention,而不是关于QKV的attention,这样复杂度降低了一个量级,实现以存换算。每次Decode阶段只需要把最新的生成的Token输入进去,拿之前的KVCache来做attention,预测下一个Token,而每生成一个Token,都需要访问所有历史的KVCache,计算量小,但内存带宽压力大。Decode是典型的Bandwidth-bound阶段。
LLM推理的核心瓶颈在于逐个Token生成的Decode阶段,其本质受限于内存带宽,而非计算峰值。LLM推理阶段包括Prefill阶段和Decode阶段,其中Prefill阶段类似于训练,需要同时处理输入序列的所有Token,本质上具有高度并行性,通常受计算能力限制。相比之下,Decode阶段本质上是顺序执行的,每一步仅生成一个输出Token,这使其性能受限于内存带宽。大模型推理过程中90%以上的时间耗费在Decode阶段,单线程生成首个Token的延迟一般不超过0.1s,后续每生成一个Token的量级大概为50ms。
2.2 LPU具备更快的内存带宽,可缩短大模型推理过程中的延迟
2.2.1 LPU采用SRAM作为存储介质,解决大模型推理阶段面临的内存带宽受限问题
LPU采用SRAM作为存储介质,解决大模型推理阶段面临的内存带宽受限问题。在Groq的设计中,芯片内部没有调度器。每一比特数据在芯片内部的流动路径、在哪个时钟周期到达哪个功能单元,全都在编译阶段由算法计算完成,带来了硬件不再需要为了“猜测”指令流向而浪费晶体管和功耗。同时,Groq采用SRAM替代HBM,带来了确定性时延、数据流设计等优势。Groq通过静态调度,去除了所有与计算无关的“控制开销”,而在传统CPU/GPU中,约有60%-80%的能量消耗在数据的搬运、缓存管理和指令调度上。
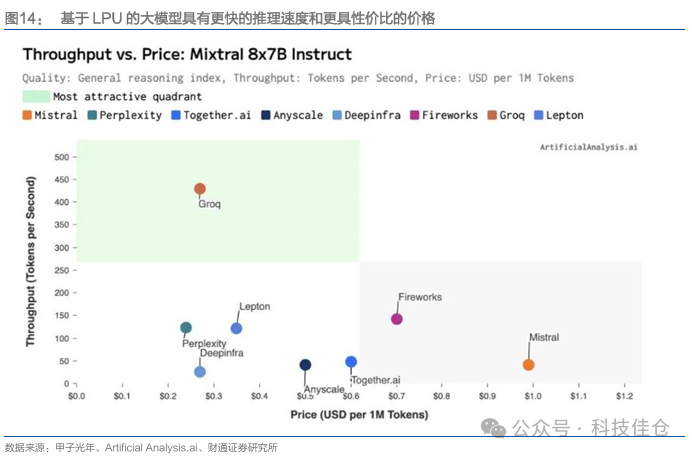
2.2.2 基于LPU的大模型具有更快的推理速度和更具性价比的价格
基于LPU的大模型具有更快的推理速度和更具性价比的价格。根据Articical Analysis的数据显示,Grop推出的Mixtral 8×7B Instruct API,以每秒处理约430个Token的速度,且每百万个Token的价格仅为0.27美元。
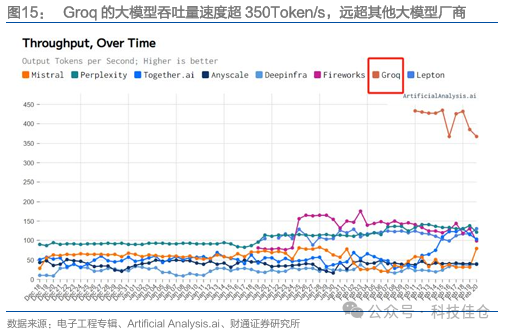
3
LPU具备广阔潜在发展空间,已步入量产初期
3.1 Tokens消耗量大幅增长带动推理芯片市场规模高增长,LPU具备广阔潜在发展空间
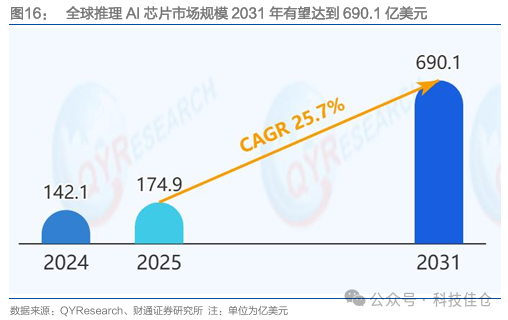
推理Tokens消耗量大幅增长,推理芯片市场规模迎来高增长。从Tokens使用角度来看,据国家数据局,2024年初我国日均Token的消耗量为1000亿,截至2025年6月底,日均Token消耗量已突破30万亿,1年半的时间增长了300多倍;数据显示,中国整体日均Token消耗于2025年中突破30万亿,2026年2月主流大模型合计日均Token消耗已到180万亿级别。2025年3月,据QYResearch数据,2024年全球推理AI芯片市场规模大约为142.1亿美元,预计2031年将达到690.1亿美元,2025年-2031年CAGR为25.7%。
推理需求持续高增长,推理芯片市场规模再度上调预期。2026M3,据星宸科技,当前AI时代已从训练上半场迈入推理下半场,随着Agent时代到来,推理需求将持续高增长。2026年全球AI芯片市场规模预计达2800亿美元,其中推理芯片占比52%,规模约1450亿美元,年复合增速超50%,而LPU在能效比、性价比、时延等方面显著优于GPU,有望成为推理市场的主导技术路线,市场潜力巨大。
3.2 海外已进入量产初期,国内已推出LPU产品
海外:Groq与英伟达签订非独家推理技术许可协议,AI芯片产量提高有望进入量产初期。Groq成立于2016年,创始人Jonathan Ross是前谷歌高级工程师,也是谷歌自研AI芯片TPU团队的核心成员,产品主管John Barrus曾在谷歌及亚马逊团队担任产品高管。公司产品LPU是一款新型的AI芯片,采用格罗方德的14nm工艺,23M8,Groq宣布,三星的Taylor工厂将生产其4nmAI加速器芯片。25M12,Groq宣布与Nvidia签订非独家授权协议,授权Nvidia推理技术,作为协议的一部分,Groq创始人Jonathan Ross、总裁Sunny Madra将加入Nvidia,共同推动和扩展授权技术的发展,Groq将继续作为独立公司运营。26M3,Groq决定将2025年委托三星电子晶圆代工生产的AI芯片产能,从约9000片晶圆提升至1.5万片晶圆,有望于2026年进入商业化量产初期。

国内:元川微为国内LPU架构先行者,已推出LPU产品。元川微成立于2025年9月,专注于AI推理算力芯片设计,聚焦端边侧智能场景,是国内领先的基于LPU架构的算力芯片设计企业。依托自研的硬数据流架构与全资源编译器等核心技术,推出了面向大模型、多模态和端侧应用场景的Mountain(算力)、River(Agent)两大系列LPU+产品。
4
投资建议
LPU作为一款新的面向大模型推理阶段的定制芯片,采用TSP架构实现了确定性的指令执行顺序和时间,可缩短大模型推理过程中的延迟,提高用户使用体验感。目前推理Tokens消耗量大幅增长,中国整体日均Token消耗于2025年中突破30万亿,2026年2月主流大模型合计日均Token消耗已到180万亿级别,增长6倍,所需的推理芯片市场规模持续高增长,LPU潜在替代空间巨大,同时我们认为LPU受益于低推理延时的优异表现,有望实现快速渗透,我们看好LPU逐渐渗透过程中带来的高成长性以及LPU以系统架构出货形式时所带来的PCB相关机会,建议关注:智微智能(参股元川微)、星宸科技(多轮增资元川微)、沪电股份(英伟达PCB供应商)、胜宏科技(英伟达PCB供应商)、深南电路(英伟达PCB供应商)。
5
风险提示
AI技术迭代不及预期的风险:若AI技术整体迭代不及预期,无法达到预想效果,则可实现功能可能不及预期,影响大模型推理需求,进而对行业产生不利影响;
大模型发展不及预期的风险:若大模型技术发展不及预期,无法提供更符合使用者使用需求的功能,可能对大模型推理需求产生影响,进而对算力需求产生影响;
LPU行业发展不及预期的风险:若LPU行业发展不及预期,可能影响LPU的渗透情况,进而影响产业发展。
团队成员
唐佳:SAC执业证号S0160525110002,厦门大学电气工程本科,西南财经大学金融学硕士,曾就职于中信证券研究部任电子分析师,目前任财通证券电子&新科技首席分析师。二级市场从来都不缺机会,我们更愿意走进产业,抓大趋势,做有赚钱效应的研究。
吴姣晨:SAC执业证号S0160522090001,曾供职于西部证券股份有限公司,墨尔本大学硕士,主要研究方向为PCB行业、功率&sic行业、安防行业等。
王雨然:SAC执业证号S0160524120003,莫纳什大学硕士,主要研究方向为半导体设备、零部件、材料,曾任职于产业界龙头公司
朱陈星:SAC执业证号S0160525020002,伦敦大学硕士,主要研究方向为芯片设计,国产算力,光通信。
詹小瑁:SAC执业证号S0160525120008,曾供职于华福证券股份有限公司、平安证券股份有限公司,中南财经政法大学硕士,主要研究方向为半导体。
周勃宇:SAC执业证号S0160126010016,曾供职于开源证券股份有限公司,上海财经大学硕士,主要研究方向为海外算力、被动元器件、面板。
证券研究报告:《LPU专题报告一:架构创新突破大模型推理延迟瓶颈,广阔市场空间有望快速放量》
对外发布时间:2026年3月16日
报告发布机构:财通证券股份有限公司(已获中国证监会许可的证券投资咨询业务资格)
本报告分析师:
唐佳 SAC 执业证书编号:S0160525110002
联系人:
周勃宇 SAC 执业证书编号:S0160126010016

>>>查看更多:股市要闻
